基于Python提取《平凡的世界》人物关系并绘制共现图
概述
《平凡的世界》是中国作家路遥创作的一部全景式地表现中国当代城乡社会生活的百万字长篇小说。1986年12月首次出版。该书以中国70年代中期到80年代中期十年间为背景,通过复杂的矛盾纠葛,以孙少安和孙少平两兄弟为中心,刻画了当时社会各阶层众多普通人的形象,深刻地展示了普通人在大时代历史进程中所走过的艰难曲折的道路。 该书时间跨度从1975年初到1985年,全景式地反映了这十年间我国城乡社会生活的巨大历史性变迁。如此庞大的工程,路遥采用了“三线组合法”,小说所涉及人物众多,人物之间关系错综复杂,梳理起来具有一定的难度。
共现:即共同出现,关系紧密的人物往往会在文本中多段内同时出现,可以通过查找文本中已确定的人名,计算不同人物共同出现的次数和比率来确定人物之间关系紧密的程度。当比率大于某一阈值,我们认为两个人物间存在某种联系。
本文将基于简单共现关系,编写 python 代码从纯文本中提取出人物关系网络,并用 pycharts 将生成的网络可视化。
数据来源
《平凡的世界》小说 txt 来源网址:https://www.txt80.com/down/txt...
《平凡的世界》情节及人物称谓介绍:https://baike.baidu.com/item/...
主要人物提取
通过 jieba.posseg 对文本进行分词,同时生成每个词的词性,词性 nr 表示人名。查找词性中含有 nr 的词写入字典。将字典转化为列表倒序排列,由此统计出小说的主要人物。
import jieba.posseg as pseg
txt_filename = './data/平凡的世界.txt'
result_filename = './output/平凡的世界_pseg.csv'
# 从文件读取文本
txt_file = open(txt_filename, 'r', encoding='utf-8')
content = txt_file.read()
txt_file.close()
print('文件读取完成')
# 添加自定义字典
# jieba.load_userdict('./data/userdict_pseg.txt')
# 分词
words = pseg.cut(content) # peseg.cut返回生成器
print('分词完成')
# 用字典统计每个人物名词的出现次数
word_dict = {}
print('正在统计所有词中的人物名词……')
count = 0 # 用于记录已处理的名词数
for one in words:
# 为便于处理,用w记录本次循环检查的“词”,f记录对应的“词性”
w = one.word
f = one.flag
if len(w) == 1: # 忽略单字
continue
if 'nr' in f: # 如果该词的词性中包含'nr',即这是个人物名词,……
if w in word_dict.keys(): # 如果该词已经在词典中,……
word_dict[w] = word_dict[w] + 1
else: # 如果该词不在词典中,……
word_dict[w] = 1
print()
print('人物名词统计完成')
# 把字典转成列表,并按原先“键值对”中的“值”从大到小排序
items_list = list(word_dict.items())
items_list.sort(key=lambda x: x[1], reverse=True)
print('排序完成')
result_file = open(result_filename, 'w')
result_file.write('人物,出现次数\n')
for i in range(num):
word, cnt = items_list[i]
message = str(i + 1) + '. ' + word + '\t' + str(cnt)
print(message)
result_file.write(word + ',' + str(cnt) + '\n')
result_file.close()
print('已写入文件:' + result_filename)
根据结果,确定非人名和人物别称,在下一步中进行删除。
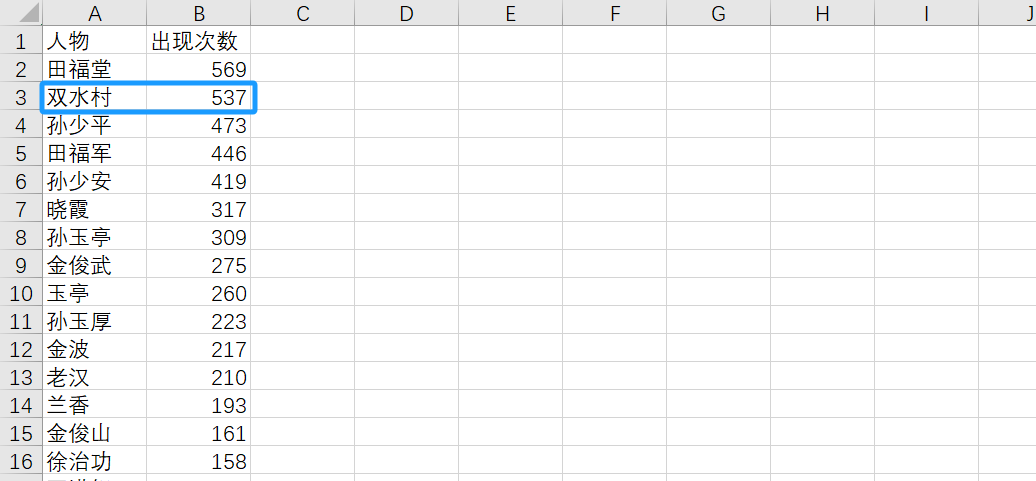

共现关系提取
用 for 循环逐行处理文本中的人名(类似于握手问题),注意跳过上一步确定的非人名词,以及处理不同称谓的问题。


由于人名处理耗时较长,在 for 循环的上一行设置 progress=0,之后在每次循环中监控进度,打印进度条,对使用者更加友好。

import jieba.posseg as pseg
##--- 第0步:准备工作,重要变量的声明
# 输入文件
txt_file_name = './data/平凡的世界.txt'
# 输出文件
node_file_name = './output/平凡的世界-人物节点.csv'
link_file_name = './output/平凡的世界-人物连接.csv'
# 打开文件,读入文字
txt_file = open(txt_file_name, 'r', encoding='utf-8')
line_list = txt_file.readlines()
txt_file.close()
##--- 第1步:生成基础数据(一个列表,一个字典)
line_name_list = [] # 每个段落出现的人物列表
name_cnt_dict = {} # 统计人物出现次数
# !!设置忽略词的列表
ignore_list = ['双水村', '老汉', '师傅', '明白', '和晓霞', '阳光', '和润叶',
'米家镇', '洪水', '金家湾']
print('正在分段统计……')
print('已处理词数:')
progress = 0 # 用于计算进度条
for line in line_list: # 逐个段落循环处理
word_gen = pseg.cut(line) # peseg.cut返回分词结果,“生成器”类型
line_name_list.append([])
for one in word_gen:
word = one.word
flag = one.flag
if len(word) == 1: # 跳过单字词
continue
if word in ignore_list: # 跳过标记忽略的人名
continue
# 对指代同一人物的名词进行合并
if word == '玉厚':
word = '孙玉厚'
if word == '福堂':
word = '田福堂'
if word == '红梅':
word = '郝红梅'
if word == '晓霞':
word = '田晓霞'
if word == '玉亭':
word = '孙玉亭'
if flag == 'nr':
line_name_list[-1].append(word)
if word in name_cnt_dict.keys():
name_cnt_dict[word] = name_cnt_dict[word] + 1
else:
name_cnt_dict[word] = 1
# 因为词性分析耗时很长,所以需要打印进度条,以免用户误以为死机了
progress = progress + 1
progress_quo = int(progress / 1000)
progress_mod = progress % 1000 # 取模,即做除法得到的余数
if progress_mod == 0: # 每逢整千的数,打印一次进度
# print('---已处理词数(千):' + str(progress_quo))
print('\r' + '-' * progress_quo + '> ' \
+ str(progress_quo) + '千', end='')
# 循环结束点
print()
print('基础数据处理完成')
##--- 第2步:用字典统计人名“共现”数量(relation_dict)
relation_dict = {}
# 只统计出现次数达到限制数的人名
name_cnt_limit = 50
for line_name in line_name_list:
for name1 in line_name:
# 判断该人物name1是否在字典中
if name1 in relation_dict.keys():
pass # 如果已经在字典中,继续后面的统计工作
elif name_cnt_dict[name1] >= name_cnt_limit: # 只统计出现较多的人物
relation_dict[name1] = {} # 添加到字典
else: # 跳过出现次数较少的人物
continue
# 统计name1与本段的所有人名(除了name1自身)的共现数量
for name2 in line_name:
if name2 == name1 or name_cnt_dict[name2] < name_cnt_limit:
# 不统计name1自身;不统计出现较少的人物
continue
if name2 in relation_dict[name1].keys():
relation_dict[name1][name2] = relation_dict[name1][name2] + 1
else:
relation_dict[name1][name2] = 1
print('共现统计完成,仅统计出现次数达到' + str(name_cnt_limit) + '及以上的人物')
##--- 第3步:输出统计结果
# 字典转成列表,按出现次数排序
item_list = list(name_cnt_dict.items())
item_list.sort(key=lambda x: x[1], reverse=True)
## 导出节点文件
node_file = open(node_file_name, 'w')
# 节点文件,格式:Name,Weight -> 人名,出现次数
node_file.write('Name,Weight\n')
node_cnt = 0 # 累计写入文件的节点数量
for name, cnt in item_list:
if cnt >= name_cnt_limit: # 只输出出现较多的人物
node_file.write(name + ',' + str(cnt) + '\n')
node_cnt = node_cnt + 1
node_file.close()
print('人物数量:' + str(node_cnt))
print('已写入文件:' + node_file_name)
## 导出连接文件
# 共现数可以看做是连接的权重,只导出权重达到限制数的连接
link_cnt_limit = 10
print('只导出数量达到' + str(link_cnt_limit) + '及以上的连接')
link_file = open(link_file_name, 'w')
# 连接文件,格式:Source,Target,Weight -> 人名1,人名2,共现数量
link_file.write('Source,Target,Weight\n')
link_cnt = 0 # 累计写入文件的连接数量
for name1, link_dict in relation_dict.items():
for name2, link in link_dict.items():
if link >= link_cnt_limit: # 只输出权重较大的连接
link_file.write(name1 + ',' + name2 + ',' + str(link) + '\n')
link_cnt = link_cnt + 1
link_file.close()
print('连接数量:' + str(link_cnt))
print('已写入文件:' + link_file_name)
可视化处理
读入前面两步的信息,用pycharts的graph类图绘制。
from pyecharts import options as opts
from pyecharts.charts import Graph
##--- 第0步:准备工作
# 输入文件
node_file_name = './data/平凡的世界-人物节点.csv'
link_file_name = './data/平凡的世界-人物连接.csv'
#node_file_name = './data/三国演义-人物节点.csv'
#link_file_name = './data/三国演义-人物连接.csv'
# 输出文件
out_file_name = './output/关系图-平凡的世界.html'
##--- 第1步:从文件读入节点和连接信息
node_file = open(node_file_name, 'r')
node_line_list = node_file.readlines()
node_file.close()
del node_line_list[0] # 删除标题行
link_file = open(link_file_name, 'r')
link_line_list = link_file.readlines()
link_file.close()
del link_line_list[0] # 删除标题行
##--- 第2步:解析读入的信息,存入列表
node_in_graph = []
for one_line in node_line_list:
one_line = one_line.strip('\n')
one_line_list = one_line.split(',')
node_in_graph.append(opts.GraphNode(
name=one_line_list[0],
value=int(one_line_list[1]),
symbol_size=int(one_line_list[1])/20)) # 手动调整节点的尺寸
link_in_graph = []
for one_line in link_line_list:
one_line = one_line.strip('\n')
one_line_list = one_line.split(',')
link_in_graph.append(opts.GraphLink(
source=one_line_list[0],
target=one_line_list[1],
value=int(one_line_list[2])))
##--- 第3步:画图
c = Graph()
c.add("",
node_in_graph,
link_in_graph,
edge_length=[10,50],
repulsion=5000,
layout="force", # "force"-力引导布局,"circular"-环形布局
)
c.set_global_opts(title_opts=opts.TitleOpts(title="《平凡的世界》人物共现关系图"))
c.render(out_file_name)
最后生成动态网络图如下:
延伸
本文是在《计算机科学与编程入门》课程作业的启发下完成的。之所以选择《平凡的世界》作为实践材料,一方面是因为它曾给我带来深刻影响,另一方面是因为它篇幅长、人物多、关系复杂,适合用作共现关系研究。 在作业要求的基础上,为了梳理学习思路,检验学习成果,我增添了一些 html 和 css 的编排。在实践过程中,对 css 的层叠嵌套和盒子模型有了更深入的理解。 同时,为了使网页更具启发价值,我在chatgpt的帮助下增添了可复制代码框功能,每个代码框中的python代码借鉴自老师课堂讲授源码。
全部文件及代码已上传至本人github(https://github.com/hutingting20021120/...)normalworld 文件夹。